Abstract
Speech-driven 3D talking-head animation often exhibits uncontrolled phenomena--cross-modal misalignment, speech–expression mismatches, and abrupt transitions--that degrade emotional naturalness
and user experience. Compensatory Control Theory (CCT) in psychology holds that when individuals perceive a loss of control, they actively seek to restore order to alleviate anxiety and regain
psychological balance. Inspired by this insight, we reinterpret these uncontrolled phenomena as ``loss-of-control'' events, and design compensatory mechanisms to restore ``control''.
Based on this perspective, we propose CCTalker,
a diffusion-based facial animation generation framework that emulates the full CCT cycle of ``loss-of-control -> compensation -> order restoration” to enhance expressivity in generated
animations. Specifically, CCTalker integrates CCT into three collaborative modules. Control–Sense Modeling quantifies target emotion categories and discrete intensities or infers continuous control
strength from audio dynamics, monitors deviations in generated expressions, and applies corrective adjustments to ensure visual-emotion alignment.Compensatory Dynamic Enhancement uses dynamic
region detection and strength combiner to identify critical vertices and routes them to the EnhancementNetwork for strengthening under-articulated motion and to the SmoothingNetwork for suppressing
abrupt deformation, thereby recovering lost geometric details and maintaining animation coherence. Information Order Modeling enforces CCT-based constraints to realign cross-modal emotional
cues and restore temporal synchronization and overall sequence order between speech and facial motion. Experiments on the 3DMEAD and BIWI datasets demonstrate that CCTalker outperforms state-of-the-art
baselines, validating the effectiveness of CCT mechanisms for generating natural and expressive 3D facial animations.
Proposed Method
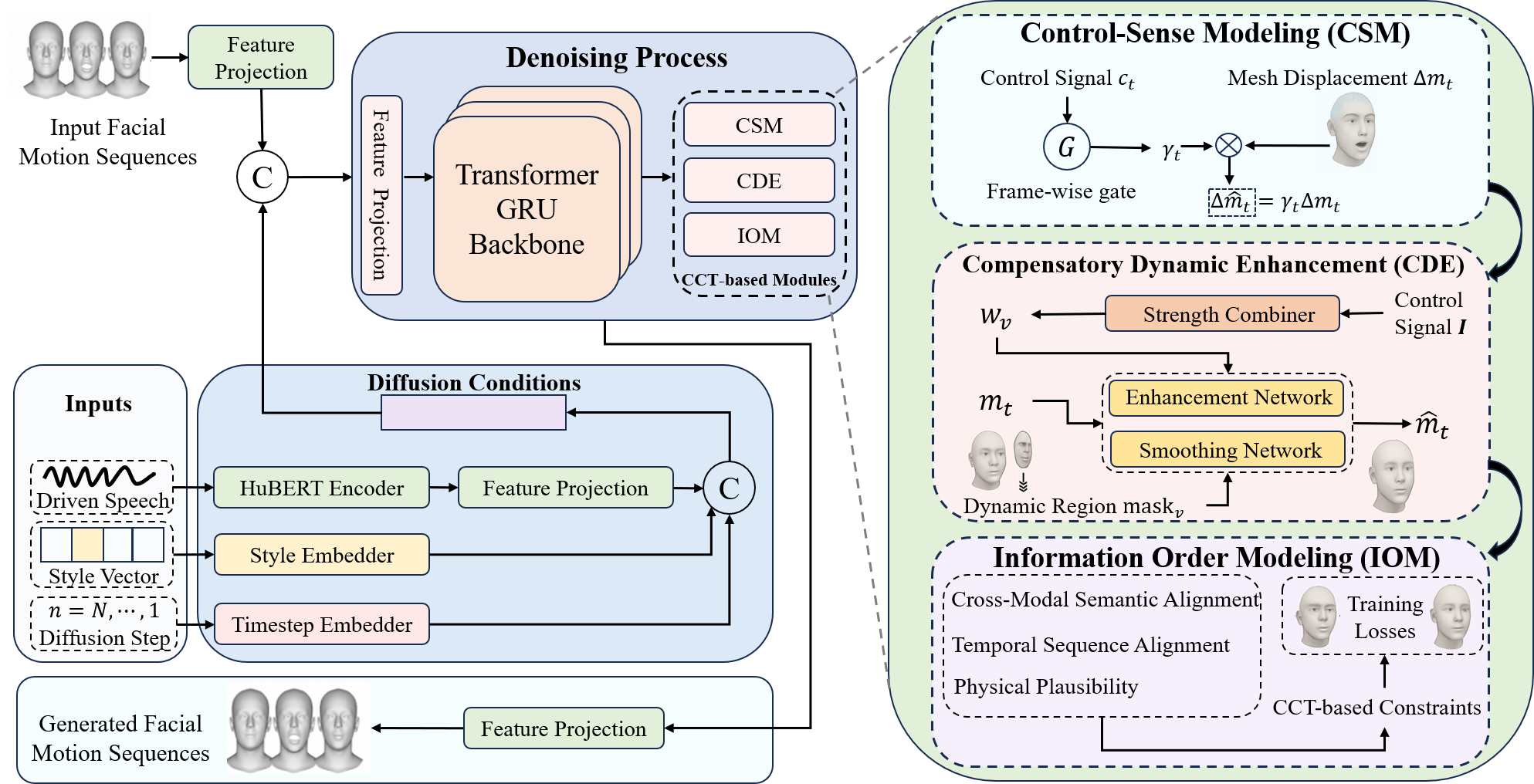
Illustration of the proposed CCTalker. The left half shows a diffusion‐based denoiser, conditioning on HuBERT audio features, style embeddings,
and timestep MLP, built on a Transformer+GRU backbone, with three CCT‐inspired modules (right half) that
contain the “loss-of-control -> compensation -> order restoration” cycle:
(1) Control–Sense Modeling gates mesh residuals via $\gamma_t$;
(2) Compensatory Dynamic Enhancement uses per‐vertex speed masks and Strength Combiner weights to route vertices through high‐frequency enhancement
or low‐frequency smoothing;
(3) Information Order Modeling enforces semantic alignment, temporal coherence, and physical plausibility.